# Compiler-projekt - Overblik
Formålet med dette dokument er at give indsigt i projektet og de teoretiske elementer, som det består af. Projektet er i et meget tidligt udviklingsstadie. Af denne grund er dokumentet både forklarende af nuværende dele (28.4.2026) og spekulativ på de dele, som ikke er udviklet endnu.
## Abstrakt
Projektets formål er at bygge high level optimizing compiler med modulær compiler-infrastruktur. Kildekilde i form af et bespoke programmeringssprog parses, valideres, sænkes og optimeres, og bruges til at generere assembly til afvikling på VM og ISA. Compileren er bygget op af en serie af trin, som transformerer programmet til forskellige midlertigie repræsentationer, der bruges til at udvinde information til at omskrive programmet.
## Implementering
Compileren selv er skrevet i Typescript med Deno. Implementeringen bruger diverse features fra Typescript og Javascript tilfordel for ergonomi. Implementeringen bruger også forskellige features og teknikker, som forbedre compilerens ressourceforbrug og afviklingshastighed.
## Kildekode
Compilerens frontend er lavet til et bespoke programmeringssprog, som fornuværende er døbt *ethlang*.
Eksempel på syntaks:
```rs
fn add(lhs: i64, rhs: i64) -> i64
{
return lhs + rhs;
}
fn main()
{
// a og b er variable
let a: i64 = 5;
let b = add(a, 3);
if b > 7 {
puts("b er større end 7\n");
} else {
puts("b er ikke større end 7\n");
}
while b <= 7 {
b = b + 1;
}
let c: *mut i64 = &mut a;
*c = 123;
let d = [1, 2, 3];
d[1] = 321;
}
```
Det ses, at syntaksen er inspireret af Rust. Der understøttes almene programmeringskonstruktioner som if-statements, variabler, funktioner, løkker og arrays. Derudover også eksplicitte pointers.
Formålet med sproget er at være ligesom C med Rust-syntaks og forskellige features fra Rust og C++. Sproget skal kunne facilitere low level kontrol over ressourcer. Memory-håndtering er i udgangspunkt manuelt.
Det er intentionen, at sproget skal bruges til desktop-applikationer på X86_64 og systemkode til en 16-bits custom ISA emulator.
Sproget er fortrinsvis LL(1) og kan beskrives i et Context Free Grammer. Der er dog undtagelser, eksempelvis venstre side af assignment-statements og (i fremtiden) nestede `/* ... */`-kommentarer.
## Tokenization
Dette trin kildekode i form af tekst op i en serie af tokens. Et token er en tekststykke med en bestemt token-type specificeret.
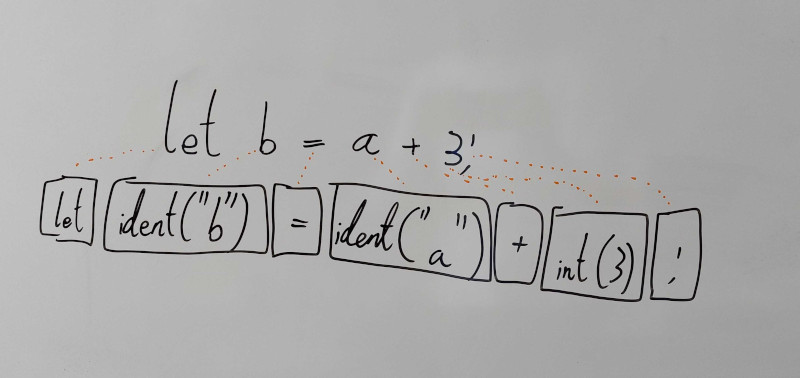
**Figur:** Visualisering af tekst og tokens.
Inkluderet i dette trin er også filtrering af kodekommentare og whitespace.
Udover sin token-type og tekst indholder tokens også dens lokation i kildekode, dvs. linje- og kolonnenummer og byteindeks i textfilen. Disse bruges til diagnosticering, eksempelvis i fejlbeskeder.
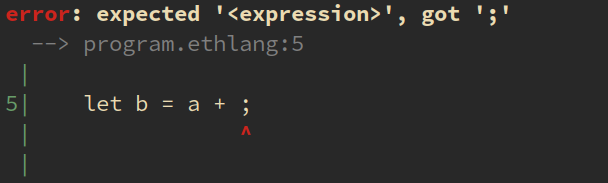
**Figur:** Eksempel på error-besked med lokation i kildekoden.
Tokenization er implementeret med en *Lexer* med en serie regler specificeret, hvor hver regel består af en Regex-mønster og en actoin-funktion.
```ts
export function tokenize(text: string, reporter: FileReporter): Tok[] {
return new Lexer()
// ignore whitespace
.add(/[ \t\r\n]+/, (_) => null)
// ignore // comments
.add(/\/\/[^\n]*/, (_) => null)
// operators, e.g. +, -, <<
.add(operatorPattern, (loc, value) => ({ type: value, value, loc }))
// identifiers and keywords, e.g. print, if
.add(/[a-zA-Z_][a-zA-Z0-9_]*/, (loc, value) => {
const type = keywordPattern.test(value) ? value : "ident";
return { type, value, loc };
})
// integer literals, e.g. 123, 32u8
.add(/(?:0|(?:[1-9][0-9]*))(?:[iu](?:8|16|32|64|size))?/, (loc, value) => {
return { type: "int", value, loc };
})
// string literals, e.g. "hello\n"
.add(/"(?:[^\\"]|\\.)*"/, (loc, literal) => {
/*...*/
})
// report unrecognized characters
.add(/./, (loc, value) => {
// ...
reporter.error(loc, `illegal character '${escapedChar}'`);
return null;
})
.lex(text);
}
```
`Lexer`-klassen og `tokenize`-funktionen er defineret i [`src/front/parse.ts`](/src/front/parse.ts).
## Parsing
Parsing består af at konvertere programmet i form af tokens til et syntakstræ (AST). Træet er en hierarkist repræsentation af programmet, hvor man i roden har en liste af top level konstruktioner som funktionsdefinitioner, og længere nede i træet er der sub-statements, expressions, sub-expressions, osv.
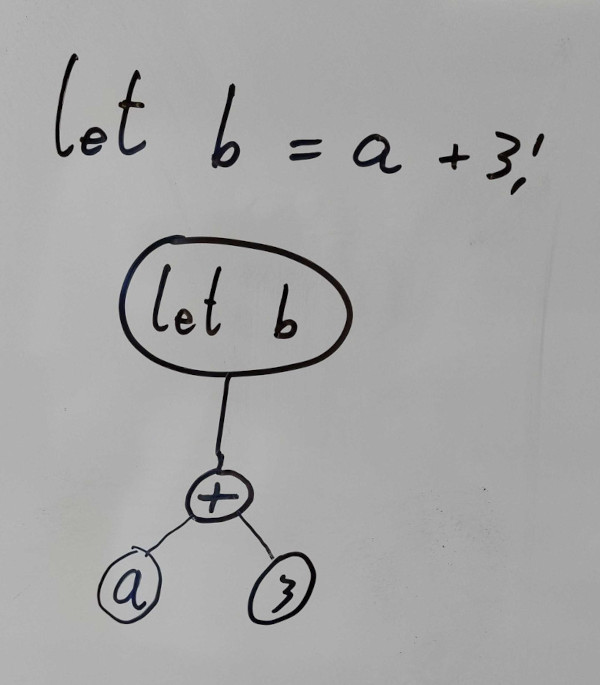
**Figur:** Eksempel på AST-repræsentation af let-statement.
Parseren har også til opgave at håndtere operator precedence. Dvs. i syntakstræet skal rækkefølgen af operators som `+` og `*` være utvetydig.
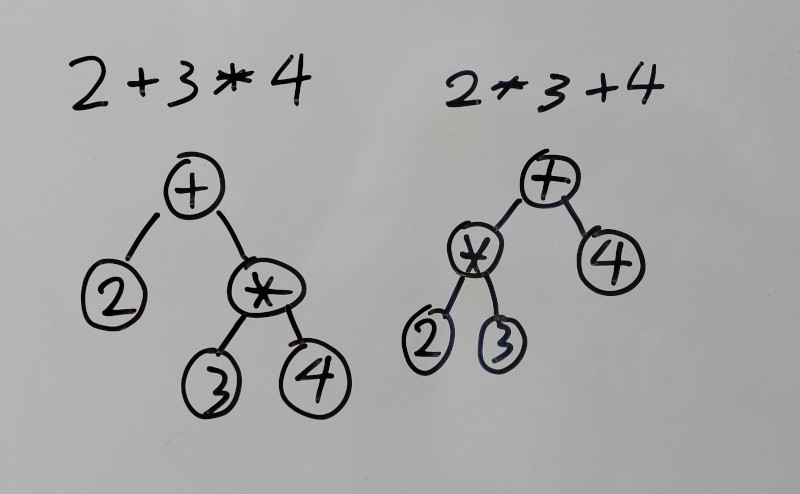
**Figur:** AST med inkorporeret operator precedence med `+` og `*`. Det ses at `*` 'binder stærkere' end `+`.
Parsing er implementeret som en `Parser`-klasse med recursive decent. Binær-operatorhåndtering er implementeret med Pratt parsing. `Parser`-klassen er defineret i [`src/front/parse.ts`](/src/front/parse.ts). AST-typerne er defineret i [`src/ast.ts`](/src/ast.ts).
## Symbol resolution
Dette trin har til opgave at sammenkæde navne med deres definitioner. Eksempelvis kan navnet `a` være defineret af et bestemt let-statement.

**Figur:** Program med symbol resolution. Det ses, at `a` i expression `%5` løses til det første let-statement `*1` og `b` i expression `%b` løses til `*2`.
Symbol resolution indeholder regler for sekvens og scoping, som diktere hvornår definitioner er relevante i forhold til deres navne.
Symbol resolution er implementeret i funktionen `resolve`. Resultatet af functionen er et map af (relevante) AST-noder og deres symboler. Et løst symbol er repræsenteret af `Sym`-typen. Typen variere i forhold til, om symbolkilden er et let-statement, funktionsparameter, osv. `Sym` og `resolve` er defineret i [`src/front/resolve.ts`](/src/front/resolve.ts).
## Validering og Type checking
Formålet med dette trin er todelt. Den ene del er at samle typeinformation og lave type-resolution. Den anden er at verificere, at programmet er korrekt struktureret. Dvs. efter dette trin, har man et well-formed AST med fyldesgørende symbol- og typeinformation.
Programmeringssproget understøtter typeinferens, dvs. det ikke er nødvendigt at specificere konkrete typer, hvis compileren kan regne ud, hvad den rigtige type er. Typeinferens er implementeret med kombineret pre og post order tree traversal på AST'en. I pre order-delen propagerer der en 'forventet' type. Denne type bruges til at løse ambiguiteter under traversen. I post order-delen bliver en type propageret op fra hver expression. I alle tilfælde hvor der er krav til typerne (eksempelvis i `+`-expressions hvor højre og venstre side skal have samme integer-type, eller i if-statements hvor betingelsen skal have bool-typen) bliver typerne håndtered med type resolution. Her udregnes den resulterende type, eller også meldes der en fejl om at typerne ikke er kompatible.
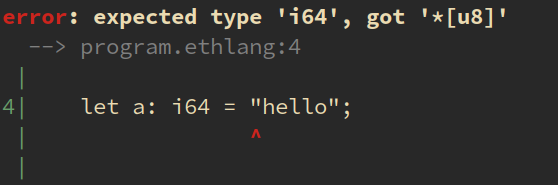
**Figur:** Fejlbesked om ukompatible typer.
Indsamlet typeinformation med løste typekonflikter indsættes i et map mellem (relevante) AST-nodes of typen.
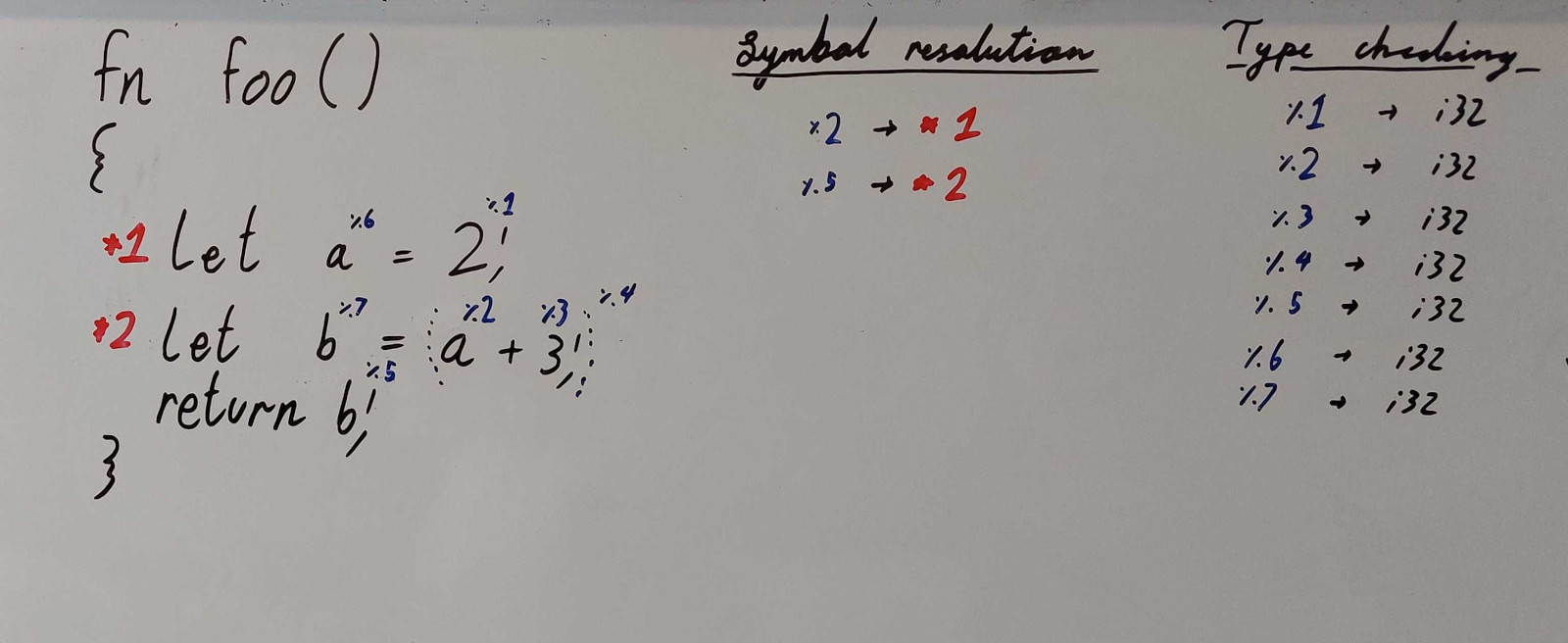
**Figur:** Typeinformation til et program. Det ses at alle expression-nodes har en associeret type.
Typer er repræsenteret af `Ty`-typen. Typer er underlagt interning[^1], dvs. compileren sørger for, at der kun findes én instans for hver slags type. Eksempelvis vil flere kald til `Ty.create(...)` med samme parametre, returner den samme instans. Typerned er interned på et hash som udregned ud fra typen.
Under type checking findes der både konkrete og abstrakte typer. Konkrete typer er typer som `i32`, `*[u8]`. Abstrakte typer er typer som type checkeren bruger internt. Dette er eksempelvis `{AnyInt}`. Denne type repræsenterer enhver int-type. Når nok information bliver tilrådighed, eksempelvis at en værdi `{AnyInt}` bliver assigned til en varbel med typen `i32`, så erstattes den abstrakte type med den konkrete. Dette gøres med en partiel tree traversal, hvor typerne for hver sub-expression omskrives.
Abstrakte typer er her et andet koncept end polymorfiske runtime-typer, som abstrakte klasser i nogle sprog. En abstrakt type i den sammenhæng, ville repræsenteres eksempelvis som en konkret pointer-type. Abstrakte typer er kun til internt brug i type checkeren.
Efter type checking skal alle typer være konkrete. Under type checking samles alle expression-typer i en container, som kan itereres over som et contiguous array. Herved kan alle typer checkes uden en ekstra travers.
Type checkeren laver andre valideringer med formål om at validere hele programmet. Et valideret programmet betyder i denne sammenhæng, at programmet overholder alle kravene, som kræves for at kunne blive kompileret. Dog er der visse valideringer, som ikke fortages i dette trin. Eksempelvis control flow-validering, som eksempelvis tjekker at man returnerer i funktioner, bliver gjort i et senere trin.
Validering, typeinferens og -checking er implementeret i `Checker`-klassen. Resultatet af denne er en `CheckedFn`-type for hver funktion. `Checker` og `CheckedFn` er defineret i [`src/front/check.ts`](/src/front/check.ts). `Ty` er defineret i [`src/ty.ts`](/src/ty.ts).
## AST-sænkning / Mid-level Intermediary Representation
I dette trin sænkes programmet fra AST-repræsentation til Mid-level Intermediary Repræsentation (MIR). MIR er en repræsentation af programmet i SSA-form med programmets Control Flow Graph (CFG) repræsenteret som Basic Blocks, programmets data flow repræsenteret som registers og phi-nodes, og programmets operationer som sekventielle instruktioner.
MIR er typestærkt ved at hver register har en associeret type. De fleste af disse typer har deres kilde i type checkeren output.
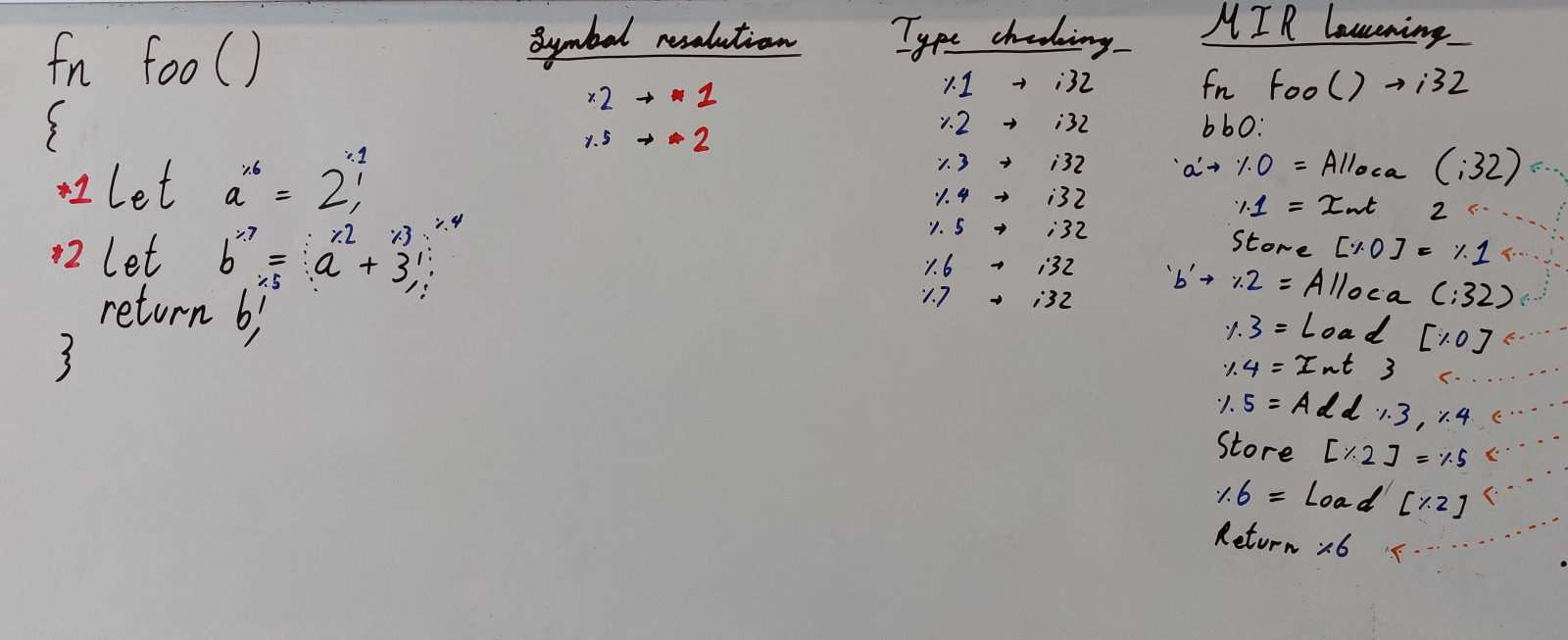
**Figur:** Funktione `foo() -> i32` med dets symbol- og typeinformation sænket til MIR. OBS de blå`%_`-labels'ne under __Type checking__ (expressions) er urelatede til samme i __MIR lowering__ (registre).
Det ses på illustrationen, hvordan let-statements bliver til `Alloca`-instruktioner, assignment (og initialisering) til `Store`-instruktioner, variabler til `Load`-instruktioner, integer literals til `Int`, return til `Return`, osv. Hver register skrives til én gang, som udgør SSA-formen. Hele koden er i Basic Block'en `bb0`.
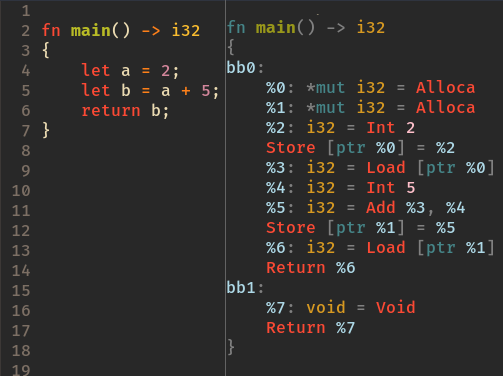
**Figur:** Eksempelprogram og dets genererede MIR. Her med compilerens syntaks-highlighting.
AST-sænkning er implementeret i `MiddleLowerer`-klassen defineret i [`src/middle.ts`](/src/middle.ts).
## MIR Control Flow-analyse
I dette trin analyseres control flow'et i MIR. Dette er primært et valideringstrin. Her fanges control flow-relaterede fejl såsom manglende return-statements.
Ikke implementeret.
### Monomorphiseing
Sproget understøtter generiske typer og parametre.
Eksempel:
```rs
fn identity(v: V) -> V
{
return v;
}
fn main()
{
let a: u8 = identity(25);
let b = identity::<*u8>(&a);
let c = identity("hello");
}
```
Efter MIR-sænkning, er generiske funktioner stadig repræsenteret som ensformige generiske funktioner. Eksempelvis vil `identity`-funktionen ligne:
```llvm
fn identity(V) -> V
{
bb0:
%0: V = Param 0
Return %0
}
fn main()
{
bb0:
%a: u8 = Alloc
%b: *u8 = Alloc
%c: *[u8] = Alloc
%0: u8 = Int 25
%1: fn identity(u8) -> u8 = Fn identity
%2: u8 = Call %1(%0)
Store [ptr %a] = %2
%3: fn identity<*u8>(*u8) -> *u8 = Fn identity
%4: *u8 = Call %3(%a)
Store [ptr %b] = %4
%5: *[u8] = Str "hello"
%6: fn identity<*[u8]>(*[u8]) -> *[u8] = Fn identity
%7: u8 = Call %6(%5)
Store [ptr %a] = %7
%8 = Void
Return %8
}
```
For at kunne kompileres videre, skal generiske funktioner konkretiseres. Dette er n process ved navn monomorphization. Her stemples generiske funktioner ud i de konkrete funktioner, som koden bruger. Eksempelvis for hver af de 3 kald til `identitity`-funktionen resultere i lignende MIR:
```llvm
fn identity(u8) -> u8
{
bb0:
%0: u8 = Param 0
Return %0
}
fn identity<*u8>(*u8) -> *u8
{
bb0:
%0: *u8 = Param 0
Return %0
}
fn identity<*[u8]>(*[u8]) -> *[u8]
{
bb0:
%0: *[u8] = Param 0
Return %0
}
fn main()
{
bb0:
...
%1: fn identity(u8) -> u8 = Fn identity
...
%3: fn identity<*u8>(*u8) -> *u8 = Fn identity<*u8>
...
%6: fn identity<*[u8]>(*[u8]) -> *[u8] = Fn identity::
...
}
```
Ikke implementeret.
## MIR-fortolkning
Dette er ikke et inkluderet trin i kompileren. Dette komponent er en VM som fortolker programmer i MIR-repræsentation.
Fortolkeren er implementeret i en `FnInterpreter`-klasse defineret i [`src/mir_interpreter.ts`](/src/mir_interpreter.ts).
## MIR-sænkning / Low-level Intermediary Representation
I dette trin sænkes programmet i MIR-form til en yderligere IR, LIR. MIR og LIR er ens på mange punkter, men med visse forskelle. Den største forskel er, at hvor MIR har high level-typer (`Ty`-typer) så har LIR et mere primitivt typesystem. I MIR, ligeledes i resten af det high-level typesystem er der forskel på signed og unsigned integers. I LIR er der ingen forskel, istedet er der signed og unsigned instruktioner.
Et eksempel på et program:
```rs
let a: i32 = 2 + 3;
let b: u32 = 2 + 3
```
i MIR-form:
```llvm
%a: *mut i32 = Alloca
%b: *mut u32 = Alloca
%0: i32 = Int 2
%1: i32 = Int 3
%2: i32 = Add %0, %1
Store [ptr %a] = %2
%3: u32 = Int 2
%4: u32 = Int 3
%5: u32 = Add %3, %4
Store [ptr %a] = %5
```
og i LIR-form:
```llvm
%a = Alloca i32, 1
%b = Alloca i32, 1
%0 = Int i32 2
%1 = Int i32 3
%2: i32 = Add signed %0, %1
Store [ptr %a] = %2
%3: u32 = Add unsigned %0, %1
Store [ptr %a] = %5
```
Dette er ikke implementeret. Pt. bliver MIR brugt de stedet LIR skal bruges.
## LIR-optimering
Formålet med dette trin er at forbedre outputtet af programmet. I det fleste tilfælde betyder dette laver ressourceforbrug, hurtigere afvikling og færre instruktioner. Dette trin består af en serie af undertrin. Undertrinnene samler specifikke informationer om programmet og omskriver repræsentationen. Trinnet kører igennem serien af undertrin flere gange.
Nogle optimeringer er platformuafhængige, mens andre er platformspecifikke eller er meget egnet til specifikke platforme. Hvilke optimizations man vælger at anvende, afhænger derfor af hvilket target man kompilerer til.
Ikke implementeret.
## Kodegenerering
De næste trin er platformafhængige. Formålet med kodegenerering er at producere et output ud fra LIR, som kan assembles og afvikles på target-platformen.
### X86_64
#### Instruction Selection
I dette trin bliver LIR sænket til X86_64 assembly-instruktioner. Outputtet af instruction selection kaldes ISEL. Stortset hver LIR-instruktion har en 1-til-1 assembly-konstruktion. Ofte bliver enkelte LIR-instruktioner til flere assembly-instruktioner.
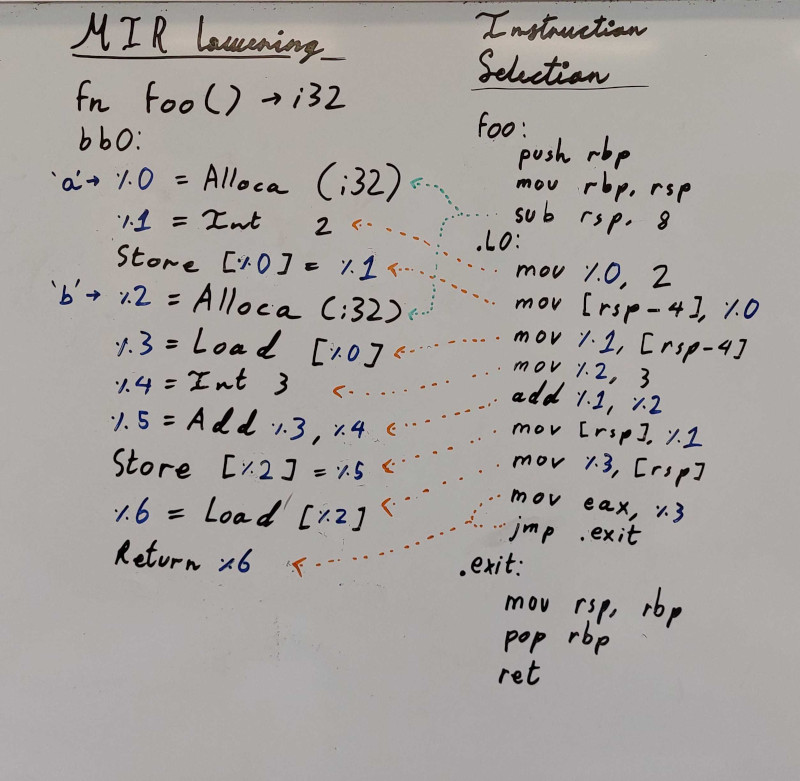
**Figur:** Forhold mellem MIR og X86_64 ISEL.
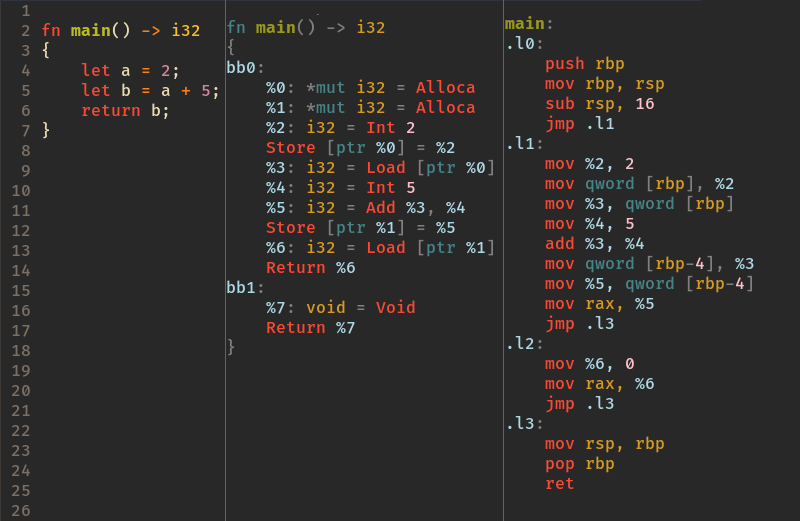
**Figur:** Eksempelprogram med MIR og output fra Instruction Selection. Her med compilerens syntaks-highlighting.
Ligesom MIR og LIR har ISEL virtuelle registre (`%_`-registre). X86_64 har visse registre, som er reserverede. Derfor kan ISEL også specificere konkrete registre.
LIR er SSA, dvs. registre kun må assignes til én gang. I X86_64 er der tilfælde, hvor registre bruges som både input- og output-registre. Dette gælder eksempelvis `add`-instruktionen, hvor første operand både er venstre side og output. Derfor tillader ISEL at registre kan re-assignes.
Dette er implementeret i `selectFnInstructions`-funktionen defineret i [`src/codegen/x86_64/isel.ts`](/src/codegen/x86_64/isel.ts).
#### Peephole optimizations
I dette trin foretages der omskrivninger af ISEL-instruktionerne. Formålet er at omskrive konstruktioner, så programmet forbedres, uden at semantikkerne ændres.
Dette er ikke implementeret.
#### Register Allocation
I dette trin vælges hvilke registre programmet skal bruge. I ISEL-repræsentationen er nogle registre konkrete registre, og andre er virtuelle registre. Formålet med dette trin er at vælge hvilke konkrete registre, der skal bruges, istedet hvor virtuelle registre.

**Figur:** Forhold mellem ISEL og register allocation.
Dette er ikke implementeret.
[^1]: https://en.wikipedia.org/wiki/Interning_(computer_science)